Publications
Chronological list of my publications
2024
-
 Learning to Land: An Unsupervised approach towards Generalization in Reinforcement Learning (PhD Thesis)Alexander QuessyAug 2024
Learning to Land: An Unsupervised approach towards Generalization in Reinforcement Learning (PhD Thesis)Alexander QuessyAug 2024Modern fixed-wing aircraft, frequently execute autonomous landings at pre-established locations under supervision. This is made possible through the use of a variety of avionics, navigation aids and air traffic systems, demonstrating an advanced and robust solution to a complex Guidance, Navigation and Control (GNC) problem. Conversely, forced landings at unprepared locations present a significant threat to safety and is a problem that will need to be addressed as a larger variety of aircraft become increasingly autonomous. This thesis investigates the problem of automating forced landings and discusses the use of machine learning methods as a stochastic approach to GNC, allowing aircraft to land autonomously in a wide-range of environments encountered in the real world. To study the problem of automating forced landings, the guidance & perception and navigation & control problems associated with forced landings are investigated initially. It is then demonstrated how aerial imagery alone is capable of locating landing sites in a scene. A methodology to build a landing site classifier from simulation is also presented, which can be utilized in the real world. The design and development of a high-speed GNC simulator for Reinforcement Learning (RL) research is then presented, with a focus on forced landings. This research demonstrates that although modern RL methods effectively generalize to problems that feature dense rewards and short time horizons, the task of automating forced landings presents a challenge. The problem inherently features a long time horizon and requires sparse rewards to generalize across a variety of landing locations. A model-based RL controller was developed to address this problem, using offline data from an expert to learn a useful policy. The general problem that was found to need addressing was exploration. The main reason these methods are unable to learn useful policies is their inability to find useful behaviors given the huge number of possible state-spaces. This is made even more difficult by the removal of external guidance in the form of dense rewards. Based upon these conclusions, the use of unsupervised RL to improve generalization with sparse rewards was investigated. The problem of exploration in complex environments was addressed by combining unsupervised RL with open-ended learning. This automatically generated increasingly complex environments via a learned curriculum. This research highlighted how recent work in auto-curricula, whilst computationally expensive, allows generalist agents to be trained automatically. To better understand the influence of data quality and quantity on model-based offline RL, unsupervised RL was combined with a safe model based controller initially trained from offline data. This work showed the importance of data diversity and quality is equally important as data quantity in learning effective safe goal-oriented control policies. The overall conclusions from both of these pieces of research is how better unsupervised representations are needed to learn useful policies without dense reward functions. Especially, given the unique GNC and safety challenges presented by real world autonomous flight.
@misc{QUESSY6, title = {Learning to Land: An Unsupervised approach towards Generalization in Reinforcement Learning (PhD Thesis)}, author = {Quessy, Alexander}, year = {2024}, month = aug, }

2023
-
 Automating Fixed Wing Forced Landings with Offline Reinforcement LearningAlexander Quessy, Thomas Richardson, and Sebastian EastIn 14^th annual International Micro Air Vehicle Conference and Competition, Sep 2023Paper no. IMAV2023-27
Automating Fixed Wing Forced Landings with Offline Reinforcement LearningAlexander Quessy, Thomas Richardson, and Sebastian EastIn 14^th annual International Micro Air Vehicle Conference and Competition, Sep 2023Paper no. IMAV2023-27Executing off-field landings in unprepared locations is a crucial skill for single-engine piston fixed-wing aircrew, particularly during sudden engine failures. The unpredictability and challenging nature of such failures often leads to flight crew overload and accidents. Further, as autonomous air vehicle capabilities advance, incorporating the ability to autonomously land following engine failure is likely to become a vital design requirement. This paper presents a unified forced landing methodology that leverages reinforcement learning (RL) to develop adaptable policies for a wide range of forced landing scenarios, with a focus on model-based offline RL. The research outlines a graphical simulation environment, procedures, and algorithms for training an RL-based controller. The effectiveness of the proposed approach is demonstrated, highlighting that offline RL is a promising solution for designing controllers capable of executing glide approaches into predetermined locations.
@inproceedings{QUESSY4, author = {Quessy, Alexander and Richardson, Thomas and East, Sebastian}, editor = {Moormann, D.}, title = {Automating Fixed Wing Forced Landings with Offline Reinforcement Learning}, year = {2023}, month = sep, day = {11-15}, booktitle = {14$^{th}$ annual International Micro Air Vehicle Conference and Competition}, address = {Aachen, Germany}, pages = {216--223}, note = {Paper no. IMAV2023-27}, } -
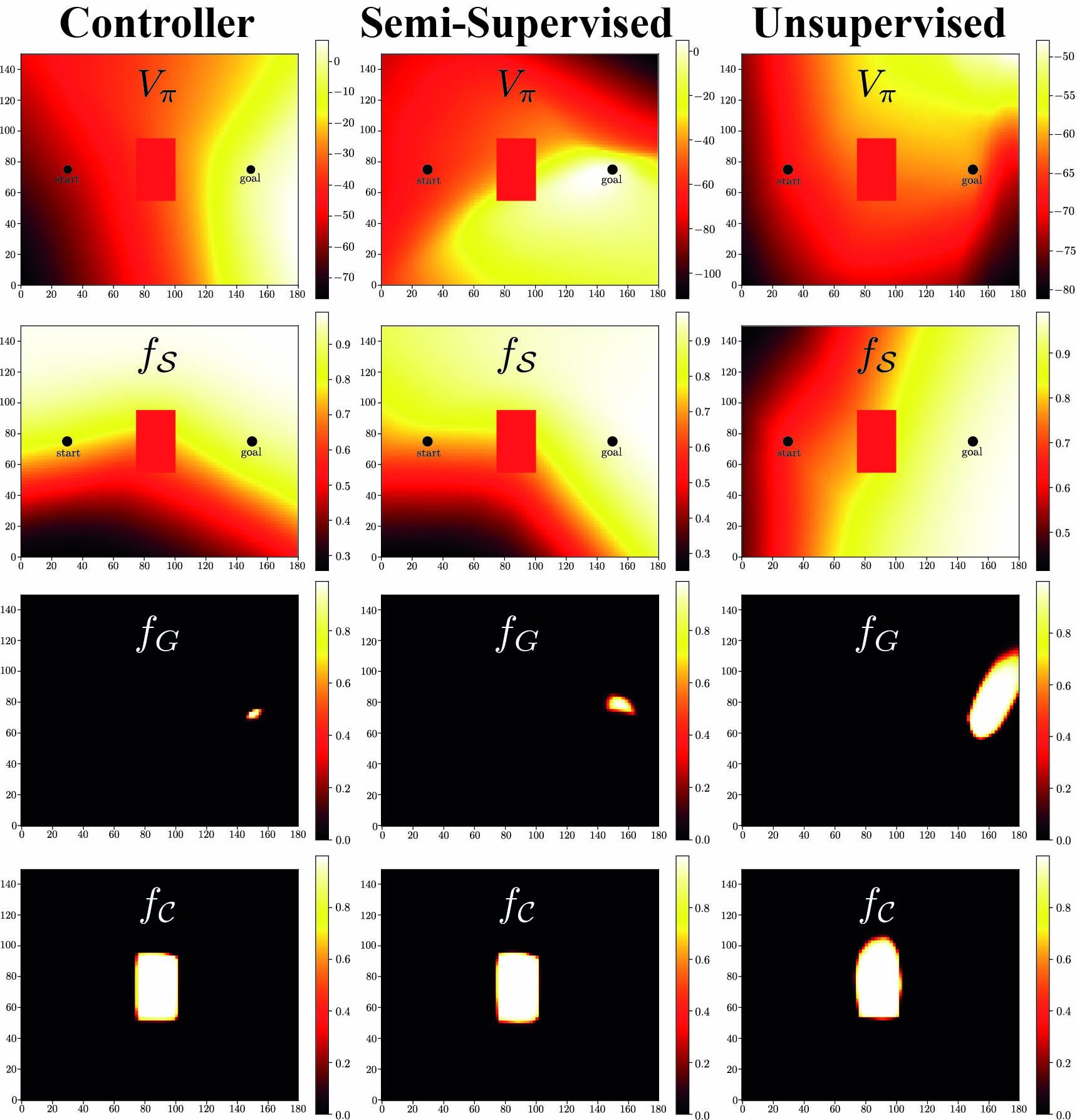 Safe Reinforcement Learning with Minimal SupervisionAlexander Quessy, Thomas Richardson, and Sebastian EastMar 2023
Safe Reinforcement Learning with Minimal SupervisionAlexander Quessy, Thomas Richardson, and Sebastian EastMar 2023Reinforcement learning (RL) in the real world necessitates the development of procedures that enable agents to explore without causing harm to themselves or others. The most successful solutions to the problem of safe RL leverage offline data to learn a safe-set, enabling safe online exploration. However, this approach to safe-learning is often constrained by the demonstrations that are available for learning. In this paper we investigate the influence of the quantity and quality of data used to train the initial safe learning problem offline on the ability to learn safe-RL policies online. Specifically, we focus on tasks with spatially extended goal states where we have few or no demonstrations available. Classically this problem is addressed either by using hand-designed controllers to generate data or by collecting user-generated demonstrations. However, these methods are often expensive and do not scale to more complex tasks and environments. To address this limitation we propose an unsupervised RL-based offline data collection procedure, to learn complex and scalable policies without the need for hand-designed controllers or user demonstrations. Our research demonstrates the significance of providing sufficient demonstrations for agents to learn optimal safe-RL policies online, and as a result, we propose optimistic forgetting, a novel online safe-RL approach that is practical for scenarios with limited data. Further, our unsupervised data collection approach highlights the need to balance diversity and optimality for safe online exploration.
@misc{QUESSY5, title = {Safe Reinforcement Learning with Minimal Supervision}, author = {Quessy, Alexander and Richardson, Thomas and East, Sebastian}, year = {2023}, month = mar, }


2022
-
 Vision based Semantic Runway Segmentation from Simulation with Deep Convolutional Neural NetworksAlexander Quessy, Thomas Richardson, and Mark HansenIn AIAA SCITECH 2022 Forum, Jan 2022
Vision based Semantic Runway Segmentation from Simulation with Deep Convolutional Neural NetworksAlexander Quessy, Thomas Richardson, and Mark HansenIn AIAA SCITECH 2022 Forum, Jan 2022Manned flight crew rely upon optical imagery to make sense of the world and carry out high level guidance, navigation \& control tasks. To advance autonomous aircraft’s capabilities and safety, programmes need to be developed that aim to achieve piloted human-level perception. We designed a simulation environment to train deep Convolutional Neural Networks (CNNs) to semantically segment objects and then test the trained network on imagery collected from the same location on a real aircraft. This approach is capable of achieving state of the art performance on the task of runway segmentation along with providing a proof of concept to rapidly generate training sets on simulation capable of being used on fixed-wing aircraft.
@inproceedings{QUESSY1, author = {Quessy, Alexander and Richardson, Thomas and Hansen, Mark}, title = {Vision based Semantic Runway Segmentation from Simulation with Deep Convolutional Neural Networks}, booktitle = {AIAA SCITECH 2022 Forum}, year = {2022}, month = jan, doi = {10.2514/6.2022-0680}, url = {https://arc.aiaa.org/doi/abs/10.2514/6.2022-0680}, } -
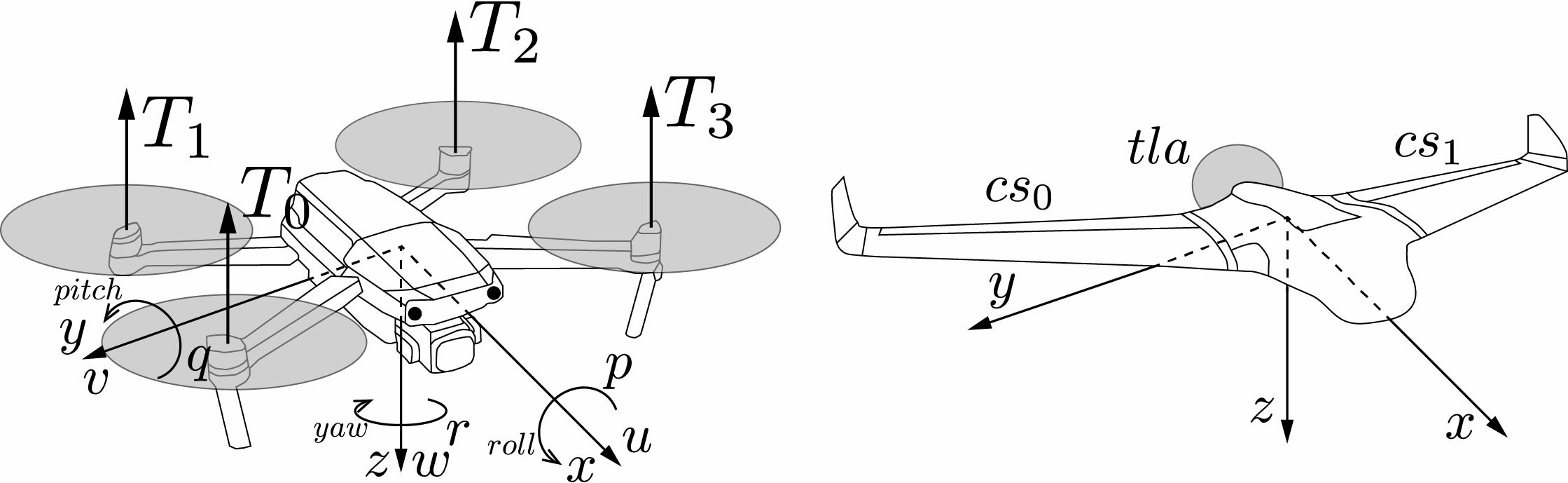 Quad2Plane: An Intermediate Training Procedure for Online Exploration in Aerial Robotics via Receding Horizon ControlAlexander Quessy, and Thomas RichardsonMar 2022
Quad2Plane: An Intermediate Training Procedure for Online Exploration in Aerial Robotics via Receding Horizon ControlAlexander Quessy, and Thomas RichardsonMar 2022Data driven robotics relies upon accurate real-world representations to learn useful policies. Despite our best-efforts, zero-shot sim-to-real transfer is still an unsolved problem, and we often need to allow our agents to explore online to learn useful policies for a given task. For many applications of field robotics online exploration is prohibitively expensive and dangerous, this is especially true in fixed-wing aerial robotics. To address these challenges we offer an intermediary solution for learning in field robotics. We investigate the use of dissimilar platform vehicle for learning and offer a procedure to mimic the behavior of one vehicle with another. We specifically consider the problem of training fixed-wing aircraft, an expensive and dangerous vehicle type, using a multi-rotor host platform. Using a Model Predictive Control approach, we design a controller capable of mimicking another vehicles behavior in both simulation and the real-world.
@misc{QUESSY2, title = {Quad2Plane: An Intermediate Training Procedure for Online Exploration in Aerial Robotics via Receding Horizon Control}, author = {Quessy, Alexander and Richardson, Thomas}, year = {2022}, month = mar, archiveprefix = {arXiv}, primaryclass = {cs.RO}, } -
 Rewardless Open-Ended Learning (ROEL)Alexander Quessy, and Thomas RichardsonJan 2022
Rewardless Open-Ended Learning (ROEL)Alexander Quessy, and Thomas RichardsonJan 2022Open-ended learning algorithms aim to automatically generate challenges and solutions to an unending sequence of learning opportunities. In Reinforcement Learning (RL) recent approaches to open-ended learning, such as Paired Open Ended Trailblazer (POET), focus on collecting a diverse set of solutions based on the novelty of an agents pre-defined reward function. In many practical RL tasks defining an effective reward function a priori is often hard and can hinder an agents ability to explore many behaviors that could ultimately be more performant. In this work we combine open-ended learning with unsupervised reinforcement learning to train agents to learn a diverse set of complex skills. We propose a procedure to combine skill-discovery via mutual information, using the POET algorithm as an open-ended framework to teach agents increasingly complex groups of diverse skills. Experimentally we demonstrate this approach yields agents capable of demonstrating identifiable skills over a range of environments, that can be extracted and utilized to solve a variety of tasks.
@misc{QUESSY3, title = {Rewardless Open-Ended Learning ({ROEL})}, author = {Quessy, Alexander and Richardson, Thomas}, year = {2022}, month = jan, url = {https://openreview.net/forum?id=g4nVdxU9RK}, }


